
From:大富豪の弟子チーム
東京のプライベートオフィスより、、、
こんにちは、
大富豪の弟子チームです。
前回に引き続き、
「賢くなる」
ための方法を、
人類が生み出した世界トップの知能、
人工知能から紐解いていきたいと思います。
ちなみに、なぜ人工知能から学ぶのか?
という問いへのアンサーは、
・人工知能は最初から賢いわけではなく、成長力がすごい
・人工知能は「学習の仕方」をプログラムされている
・人間が生み出したものであるため、「人間らしさ」を有している
・情報を扱う学問であるデータサイエンスの造詣が深まる
などなど、
これらの理由に基づいています。
つまり、人工知能について勉強すると
最短・最速で自身の成長が実現でき、
賢い人になれるというわけです。
それでは、本題に迫っていきましょう。
===========
強化学習
===========
人工知能といっても色々あるのですが、
その中に機械学習というものがあり、
さらにその中に強化学習というものがあります。
googleの囲碁AIもこの強化学習によって、
人智を超える囲碁マスターになりました。
強化学習はすごいのです。
というわけで、まずはこの強化学習の基礎を
ざっくりと理解してみよう。
強化学習において人工知能は何してるのかというと
「状態」を把握して
「取る行動」を考える
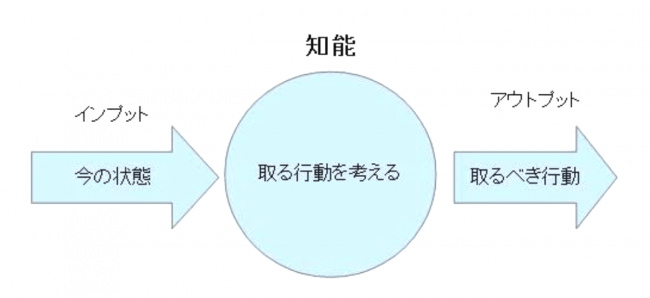
その行動によってどんな結果になるか(どれくらいリワード(報酬)が得られるか)を見て、その行動にはどの程度の価値があるのかを算出しています。
※1回の行動ではなく行動の連続
※短期的な利益ではなく最終的な利益を高める行動に価値を置く
これを繰り返しまくるのです。
(色んな行動をとったときの結果を見る)
そして、様々な行動の価値を算定し、
その中で一番価値が高い行動=とるべき行動を選択する。
みたいなことを行っています。
(イメージです)
つまり、
どういう状態でどう行動すれば最適な結果に結びつくかを予測している
ということです。
ここで気づいた人は頭がとても良いです。
「取るべき行動」の部分は、
状態によって変わるという性質があるのです。
状態が決まらないと取るべき行動も決まらないのだから
前提条件(知能へのインプット)である状況を抜きにして
アウトプットを語るという事は知能がないということ。
インプットも知能も無く、アウトプットだけがあるという状態。
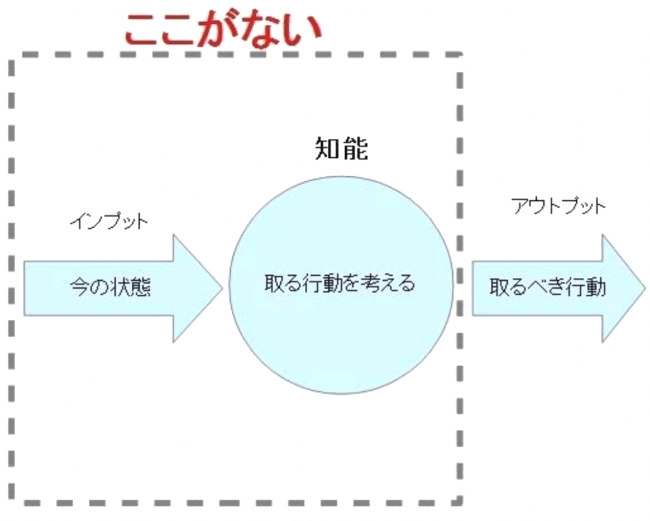
この「取るべき行動」というのが多くの人が求める情報(近道)であり、
世間で発信される情報の姿。
近道(行動情報のみ)= 知能なし
知能がないという言葉の本質が理解できたはずです。
ほとんどがこの間違っている状態だからです。
とある1つの行動をとってみても、
ある状態においては良い結果に結びつくが、
他の状態においては良い結果に結びつかないということはかなりあるのです。
言い換えれば、
行動の価値は状態に左右される。
という事でもあります。
なので、
「どういう状態」において「どういう行動」が最適なのか
という考え方が正解なわけです。
ちなみにこの知能の部分をモデルと言います。
インプットをアウトプットに変える考え方の部分がモデル。
そして、より良いモデルを作るために
行うのが学習というものなのです。
自分で良いモデルを作ろうとすると、
長い年月と膨大な行動量(試行錯誤)と高い分析能力が必要になります。
だから近道したい人は、
このモデルを一流の人から直接教わるのが良いのです。
私が永遠と、知識への投資とメンターの重要性を
説いてるのはこれが理由です。
短絡的に行動だけを求めるのではなく、モデルを教わる。
それが真の近道なのです。
インプットからアウトプットを導き出す、
「モデル」を教わるのが本当の近道です。
ー大富豪の弟子チーム
PS.
続きます。
世界でもトップ1%と言われる成功投資家や凄腕トレーダーをはじめとした人生の成功者に出会い、そんな大富豪たちに弟子として師事している。
その経験の中で、彼らが共通して持っている考え方、姿勢、習慣といった
「するべくして成功した理由」があることに気付き、投資のテクニック以前に重要となる「お金と人生に愛される人の成功法則」を発信している。
因みに「大富豪の弟子チーム」には複数のメンバーで構成されていて、様々な角度から成功のエッセンスを伝えていく。
とても腑に落ちました。
「モデル」という概念もそうですし、
今まであやふやだった思考が言語として認識すると
より明確になった気がします。
続きも楽しみにしています。